L’essentiel à retenir : les hôpitaux exploitent une diversité massive d’informations, des comptes rendus textuels, représentant 80 % des données, aux images médicales et flux administratifs. L’intelligence artificielle structure cette matière brute pour affiner les diagnostics et optimiser l’organisation des soins. La centralisation sécurisée au sein d’Entrepôts de Données de Santé constitue le socle indispensable pour valoriser ce capital tout en garantissant la confidentialité des patients.
Face à la multiplication exponentielle des informations de santé, discerner la nature exacte des données exploitées hôpitaux ia constitue un enjeu de transparence majeur pour les usagers du système de soins. Ce dossier examine comment les algorithmes valorisent ces ressources hétérogènes, allant des comptes rendus textuels non structurés aux séquences génomiques, pour affiner la précision des diagnostics médicaux. Vous comprendrez ainsi par quels procédés techniques la sécurisation et le traitement massif de ces flux d’informations permettent d’instaurer une médecine véritablement prédictive et personnalisée.
- Le cœur du réacteur : les données cliniques au service du diagnostic
- Au-delà du texte : imagerie, génomique et signaux vitaux
- L’hôpital comme une organisation : les données opérationnelles et administratives
- Transformer le chaos en information : l’ère des entrepôts de données de santé
- Un pouvoir encadré : le cadre légal et éthique de l’exploitation des données
- Les défis sur la table : biais, boîtes noires et qualité des données
Le cœur du réacteur : les données cliniques au service du diagnostic
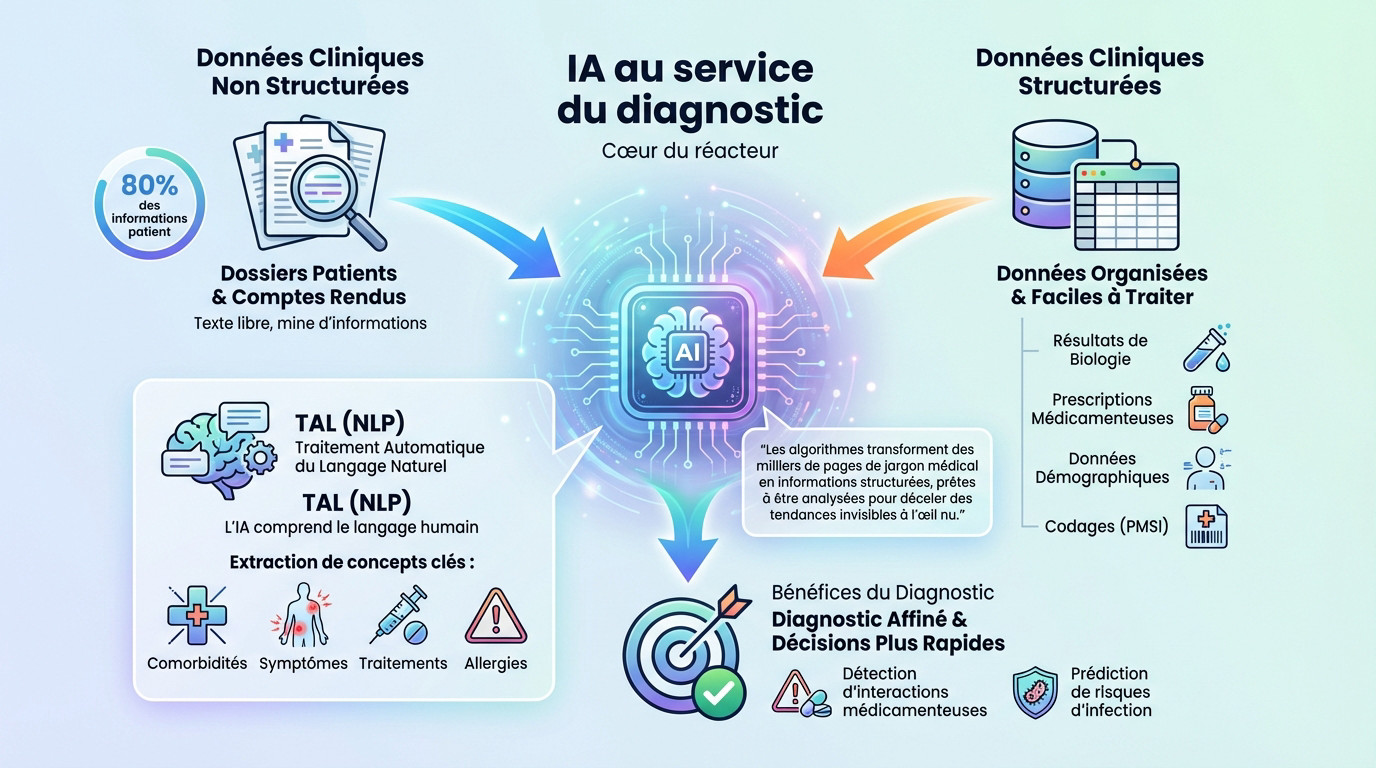
Dossiers patients et comptes rendus : la mine d’or textuelle
La majorité des données exploitées par les hôpitaux via l’IA provient des dossiers patients. Ces archives contiennent un mélange de données structurées et, surtout, de données non structurées. On y trouve les comptes rendus d’hospitalisation, les notes de consultation et les observations des soignants.
Ce texte libre est une véritable mine d’informations. Il contient des nuances sur l’état du patient, ses antécédents et l’évolution de sa pathologie. C’est là que réside la vraie valeur pour un diagnostic affiné.
Un chiffre donne le vertige : environ 80% des informations patient sont sous cette forme textuelle. Sans IA, cette richesse reste largement sous-exploitée, car impossible à analyser manuellement à grande échelle.
L’IA face au texte libre : l’enjeu de la compréhension
C’est ici qu’intervient le Traitement Automatique du Langage Naturel (TAL ou NLP). C’est la technologie qui permet aux machines de « lire » et de comprendre le langage humain contenu dans les comptes rendus.
Prenons un exemple concret d’application : l’extraction automatique de concepts cliniques. L’IA peut identifier et extraire des informations clés comme les comorbidités, les symptômes, les traitements mentionnés, ou encore les allergies, directement depuis les notes des médecins.
Les algorithmes transforment des milliers de pages de jargon médical en informations structurées, prêtes à être analysées pour déceler des tendances invisibles à l’œil nu.
Des données structurées pour des décisions plus rapides
À côté du texte libre, les hôpitaux exploitent aussi massivement des données structurées. Celles-ci sont plus faciles à traiter pour les algorithmes car elles sont déjà organisées.
- Résultats de biologie : analyses sanguines, tests microbiologiques, etc.
- Prescriptions médicamenteuses : molécules, dosages, fréquences.
- Données démographiques et administratives : âge, sexe, historique des séjours.
- Codages d’actes et de diagnostics (PMSI) : classification standardisée des pathologies et des procédures.
L’IA utilise ces données pour, par exemple, détecter des interactions médicamenteuses dangereuses ou prédire des risques d’infection.
Au-delà du texte : imagerie, génomique et signaux vitaux
Après avoir exploré la façon dont l’intelligence artificielle déchiffre les textes, il est temps d’aborder des données encore plus complexes, tant par leur nature visuelle que par leur volume massif : les images, les gènes et les signaux continus.
L’imagerie médicale, le terrain de jeu favori de l’IA
L’imagerie médicale, incluant radios, scanners et IRM, représente le domaine où l’impact de l’IA est le plus immédiat et spectaculaire. Les algorithmes d’analyse d’image y démontrent une performance redoutable. Ils traitent ces données visuelles avec une rapidité et une précision mathématique.
L’intelligence artificielle ne remplace pas le radiologue, elle agit comme un assistant infatigable pour sécuriser le diagnostic. Elle détecte des anomalies minuscules, comme des nodules ou des fractures, qu’un œil humain pourrait manquer après une longue garde. C’est un filet de sécurité indispensable pour réduire l’erreur médicale.
Prenez l’exemple de la détection des mélanomes ou de la rétinopathie diabétique. Ces modèles nécessitent l’analyse de dizaines de milliers d’images pour atteindre une fiabilité diagnostique supérieure.
La génomique et la promesse de la médecine personnalisée
Les données génomiques constituent la nouvelle frontière technique de la santé moderne. Le séquençage du génome produit une quantité astronomique de données brutes pour un seul patient. Nous sommes face à un défi de « big data » par excellence, absolument impossible à gérer sans l’intelligence artificielle.
L’IA analyse ces milliards de données pour identifier les mutations génétiques spécifiques liées aux maladies. Les cancers et les maladies rares sont les principaux bénéficiaires de cette puissance de calcul. L’outil isole l’information pertinente au cœur d’un bruit de fond immense.
C’est tout l’enjeu du Plan France Médecine Génomique 2025. Son objectif est de croiser ces données génomiques avec les données cliniques pour offrir des traitements sur mesure, enfin véritablement personnalisés.
Les données en temps réel : des capteurs aux alertes précoces
Les données issues du monitoring continu des patients transforment radicalement la surveillance hospitalière. Il s’agit de signaux vitaux captés en permanence, en réanimation ou via des dispositifs médicaux portables. Ce flux d’information ne s’arrête jamais.
L’IA analyse ces flux de rythme cardiaque ou de saturation en oxygène pour repérer des variations invisibles à l’œil nu. Elle peut détecter des dégradations subtiles et prédire une crise grave, comme un sepsis, bien avant qu’elle ne soit cliniquement évidente. Vous gagnez un temps précieux pour intervenir.
Nous passons ainsi d’une médecine réactive à une médecine prédictive et proactive. Ces alertes précoces anticipent l’urgence au lieu de la subir.
L’hôpital comme une organisation : les données opérationnelles et administratives
Piloter les flux : prédire les arrivées aux urgences
Un hôpital fonctionne exactement comme une ville qui ne dort jamais. Au-delà du soin pur, il génère des milliers de données opérationnelles sur son propre rythme interne. L’IA exploite cette mine d’or pour optimiser la machine.
Prenons l’exemple concret de la prédiction des flux de patients aux urgences. En croisant l’historique des passages avec la météo ou les données épidémiologiques, les algorithmes anticipent les pics d’affluence avec une fiabilité redoutable. Des outils comme SAUsmart atteignent 85,7 % de précision.
Cette anticipation permet d’ajuster les effectifs et les ressources bien en amont. On évite ainsi la saturation des services pour mieux accueillir les patients.
La gestion des ressources, du lit au bloc opératoire
L’enjeu s’étend à la gestion millimétrée de chaque ressource disponible. Il faut placer la bonne personne et le bon matériel, au bon endroit et au bon moment. L’improvisation n’a plus sa place dans une structure moderne.
L’IA analyse en permanence ces données de gestion pour proposer des solutions optimales et éviter les goulots d’étranglement :
- Taux d’occupation des lits : pour optimiser les hospitalisations et les sorties.
- Planification des blocs opératoires : pour réduire les temps d’attente et maximiser l’utilisation des salles.
- Gestion des stocks : pour anticiper les besoins en médicaments ou en matériel stérile.
- Horaires du personnel : pour créer des plannings plus équilibrés et adaptés à la charge de travail.
Simplifier l’administratif : facturation et codage automatisés
Parlons franchement du fardeau des données médico-administratives. C’est une part énorme du travail hospitalier, souvent répétitive et source d’erreurs humaines coûteuses. Les soignants y perdent une énergie précieuse qu’ils ne consacrent pas aux malades.
L’IA intervient efficacement dans le codage des actes (PMSI). En lisant les comptes rendus, elle suggère les codes diagnostics et procédures pertinents, faisant gagner un temps précieux aux médecins tout en améliorant la qualité du codage.
L’automatisation gère aussi la facturation complexe et les demandes de remboursement. Cela réduit les délais de paiement et allège considérablement la charge administrative.
Transformer le chaos en information : l’ère des entrepôts de données de santé
Accumuler des téraoctets de dossiers médicaux ne suffit pas. Si ces informations restent éparpillées, sales ou vulnérables, elles ne valent absolument rien. C’est ici que les infrastructures modernes entrent en scène pour raffiner ce carburant indispensable à l’intelligence artificielle.
L’Entrepôt de Données de Santé (EDS) : le coffre-fort centralisé
Un Entrepôt de Données de Santé (EDS) fonctionne comme une forteresse numérique centralisée. Il regroupe et sécurise l’intégralité des informations patients d’un groupement hospitalier. Sans ce socle technique robuste, aucune stratégie d’intelligence artificielle ne peut voir le jour.
Prenez le cas emblématique de l’EDS de l’AP-HP, qui agrège les parcours de millions de malades. Cette infrastructure colossale rend enfin possible le développement d’algorithmes prédictifs et la recherche médicale avancée.
Pour comprendre l’ampleur de ce dispositif, il est intéressant d’observer comment l’AP-HP (Assistance Publique – Hôpitaux de Paris) gère ce patrimoine inestimable.
La pseudonymisation : protéger le patient, libérer la donnée
La pseudonymisation consiste à purger les dossiers de toute mention directement identifiante. Noms, prénoms ou adresses disparaissent au profit de codes aléatoires, rendant l’identification directe impossible.
Cette étape n’est pas une option, c’est un impératif éthique. Elle autorise les chercheurs à exploiter la richesse clinique sans jamais trahir le secret médical. L’IA automatise désormais ce masquage.
Ce processus rigoureux garantit l’intégrité du système, tout comme la traçabilité des données de santé assure la sécurité tout au long de la chaîne de soins.
De la donnée brute à la donnée actionnable : le travail de qualification
Une donnée brute est inexploitable par une IA. Elle exige un nettoyage méticuleux, une structuration précise et une annotation experte.
| Type de donnée brute | Processus de transformation | Donnée prête pour l’IA |
|---|---|---|
| Compte rendu scanné | OCR + NLP | Texte numérique pseudonymisé avec comorbidités extraites |
| Note manuscrite du médecin | Transcription + structuration | Données structurées sur les symptômes |
| Image radio brute | Annotation par un expert (ex: « présence de nodule ») | Image avec zones d’intérêt délimitées |
| Séquence génomique brute | Alignement et analyse de variants | Liste de mutations génétiques pertinentes |
Un pouvoir encadré : le cadre légal et éthique de l’exploitation des données
Le RGPD et la CNIL : les gardiens de la confidentialité
Les données de santé ne sont pas des informations banales. Le RGPD les classe comme « particulièrement sensibles », ce qui impose une vigilance extrême. En principe, leur traitement est strictement interdit par la réglementation européenne. C’est une ligne rouge qu’on ne franchit pas sans raison valable.
Pourtant, l’amélioration des soins justifie parfois une exception, mais jamais sans contrôle. Cette dérogation reste soumise aux conditions strictes définies par la CNIL. Les hôpitaux doivent impérativement respecter ces garde-fous :
- Une finalité explicite et légitime.
- Une minimisation drastique des données collectées.
- Une sécurité informatique renforcée.
- Une analyse d’impact sur la vie privée (AIPD).
Pour aller plus loin sur ces obligations, référez-vous aux conditions strictes définies par la CNIL.
L’Espace Européen des Données de Santé : vers un partage facilité ?
L’Europe change la donne avec le règlement sur l’Espace Européen des Données de Santé (EEDS ou EHDS). Cette initiative vise à harmoniser la circulation des informations médicales entre les États membres. C’est un tournant majeur pour la souveraineté numérique en santé.
L’objectif est double et particulièrement ambitieux. D’abord, il s’agit de redonner aux citoyens le contrôle total sur leurs données, où qu’ils soient. Ensuite, le texte crée un cadre pour l’utilisation secondaire des données, favorisant l’innovation de manière sécurisée.
C’est une promesse concrète d’accélération pour la recherche médicale. L’accès à des jeux de données bien plus vastes permettra des avancées significatives.
L’éthique au-delà de la loi : consentement et responsabilité
La conformité légale ne suffit pas toujours ; l’éthique doit guider chaque décision. Le consentement du patient reste au centre des débats actuels. Sans une confiance absolue, tout le système de collecte s’effondre.
En recherche, on applique souvent le principe de « non-opposition ». Le patient doit être informé et garder la liberté de refuser l’usage de ses données. Cette transparence est indispensable pour légitimer l’amélioration des indicateurs de qualité et de sécurité des soins. C’est une responsabilité morale.
C’est d’ailleurs grâce à cette rigueur que l’on peut fiabiliser les indicateurs de qualité et de sécurité des soins au sein des établissements.
Les défis sur la table : biais, boîtes noires et qualité des données
Mais ce tableau ne serait pas complet sans aborder les difficultés. L’IA en santé n’est pas une solution miracle et se heurte à des obstacles techniques et éthiques de taille.
Le piège des biais algorithmiques : quand l’IA reproduit nos préjugés
Parlons franchement du biais algorithmique. Une IA est le reflet des données sur lesquelles elle est entraînée. Si les données sont biaisées, l’IA le sera aussi, c’est mathématique.
Imaginez le désastre : si un algorithme est entraîné majoritairement sur des données d’hommes caucasiens, il sera moins performant pour diagnostiquer des maladies chez les femmes ou les personnes d’autres origines.
Cela risque de renforcer les inégalités de santé existantes au lieu de les réduire. La lutte contre ces biais est un enjeu majeur.
Le mystère de la « boîte noire » : l’exigence d’une IA explicable
Un autre problème surgit avec la « boîte noire » (black box). De nombreux algorithmes, notamment en deep learning, sont si complexes qu’ils ne peuvent pas expliquer leur propre raisonnement.
Un algorithme qui sauve une vie mais ne peut expliquer pourquoi est à la fois une prouesse technique et un véritable casse-tête éthique et juridique pour le médecin.
Cette opacité est inacceptable en médecine. Un médecin doit pouvoir comprendre et justifier une décision, c’est pourquoi la recherche sur l’IA explicable (XAI) est si active actuellement.
La qualité avant la quantité : le talon d’Achille du big data
Ne vous y trompez pas, le volume ne fait pas tout. La qualité des données est bien plus déterminante pour la performance d’une IA que la simple quantité brute.
Prenez le SNDS français (Système National des Données de Santé). Bien qu’immense, il contient des erreurs car il a été conçu à des fins administratives et non médicales. Entraîner une IA dessus sans un cadre précis peut mener à des conclusions erronées.
Le nettoyage et la qualification des données, bien que fastidieux, sont une étape absolument fondamentale. Retrouvez plus de détails dans ce dossier de l’Inserm sur l’IA et la santé.
L’exploitation des données hospitalières révolutionne la médecine moderne. Du dossier patient à la gestion des flux, l’intelligence artificielle offre des diagnostics plus précis et une organisation optimisée. Toutefois, cette transformation numérique nécessite une éthique rigoureuse. La sécurisation des informations et la transparence des algorithmes demeurent essentielles pour garantir la confiance des patients.
FAQ
Quels sont les principaux types de données exploités par l’IA à l’hôpital ?
Les établissements de santé exploitent deux grandes catégories d’informations : les données structurées et les données non structurées. Les premières concernent les éléments standardisés comme les résultats d’analyses biologiques, les constantes vitales (tension, température) ou les prescriptions médicamenteuses, qui sont facilement lisibles par les systèmes informatiques.
Les secondes, qui représentent environ 80 % du volume total des données hospitalières, incluent les comptes rendus médicaux textuels, les images de radiologie ou encore les séquences génomiques. L’intelligence artificielle est aujourd’hui indispensable pour analyser cette masse d’informations hétérogènes afin d’affiner les diagnostics et personnaliser les soins.
Comment l’intelligence artificielle traite-t-elle les comptes rendus médicaux ?
L’IA utilise le Traitement Automatique du Langage Naturel (TAL ou NLP) pour décrypter et structurer les textes libres rédigés par les médecins et les soignants. Cette technologie permet à la machine de « lire » et de comprendre des milliers de pages de notes cliniques qui seraient impossibles à traiter manuellement à grande échelle.
Grâce à ce procédé, les algorithmes peuvent extraire automatiquement des concepts cliniques précis, tels que les comorbidités, les symptômes ou les antécédents du patient. Cela transforme des observations éparses en données exploitables pour la recherche médicale et l’amélioration du suivi thérapeutique.
En quoi les données administratives sont-elles utiles pour la gestion hospitalière ?
Au-delà du soin direct au patient, les données administratives et opérationnelles sont essentielles pour piloter l’organisation. Elles englobent les historiques d’admissions, les durées de séjour, les flux de facturation ainsi que les plannings des ressources humaines et matérielles.
L’analyse prédictive de ces données permet d’anticiper les pics d’activité, comme l’affluence aux urgences, et d’optimiser l’occupation des lits ou l’utilisation des blocs opératoires. Cette gestion par la donnée vise à fluidifier le parcours de soins et à réduire les temps d’attente pour les patients.
Quel rôle jouent l’imagerie et la génomique dans le Big Data de santé ?
L’imagerie médicale et la génomique génèrent des volumes de données considérables qui constituent un terrain de prédilection pour l’intelligence artificielle. En imagerie, les algorithmes analysent les pixels des scanners ou IRM pour détecter des anomalies subtiles, agissant comme une aide précieuse au diagnostic.
Concernant la génomique, le séquençage de l’ADN produit une quantité massive d’informations complexes. Le croisement de ces données génétiques avec les données cliniques permet de développer une médecine de précision, capable de proposer des traitements ciblés adaptés au profil biologique unique de chaque patient.
Comment la confidentialité des données est-elle garantie lors de leur exploitation ?
L’utilisation des données de santé est soumise à un cadre légal et éthique extrêmement strict, régi notamment par le RGPD et supervisé par la CNIL. Avant toute exploitation pour la recherche ou l’entraînement d’algorithmes, les données doivent impérativement être pseudonymisées, c’est-à-dire que les informations identifiantes sont supprimées ou masquées.
Ces informations sont ensuite centralisées dans des Entrepôts de Données de Santé (EDS) ultra-sécurisés. Ces infrastructures garantissent que l’innovation technologique et l’amélioration des soins se font toujours dans le respect absolu de la vie privée et du secret médical.